Simulation-based inference
in gravitational wave data analysis
2026-04-24
What kind of data do we have?
Strain data for the GW250114 event (Abac et al. 2025).
Glitches
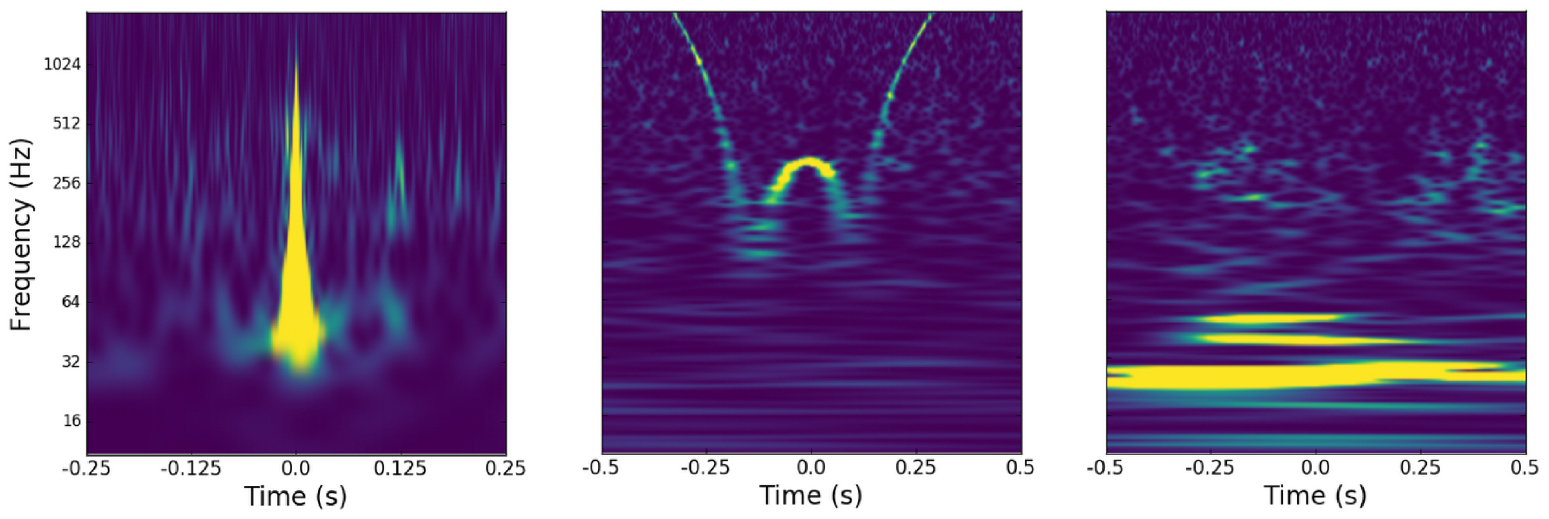
Examples of glitches in gravitational wave data (Powell 2018).
Bayesian inference
\[ \underbrace{\mathcal{L}(d | \theta, M) \pi (\theta | M)}_{\text{assumptions}} = \underbrace{p(\theta | d, M) \mathcal{Z}(d | M)}_{\text{result}} \]
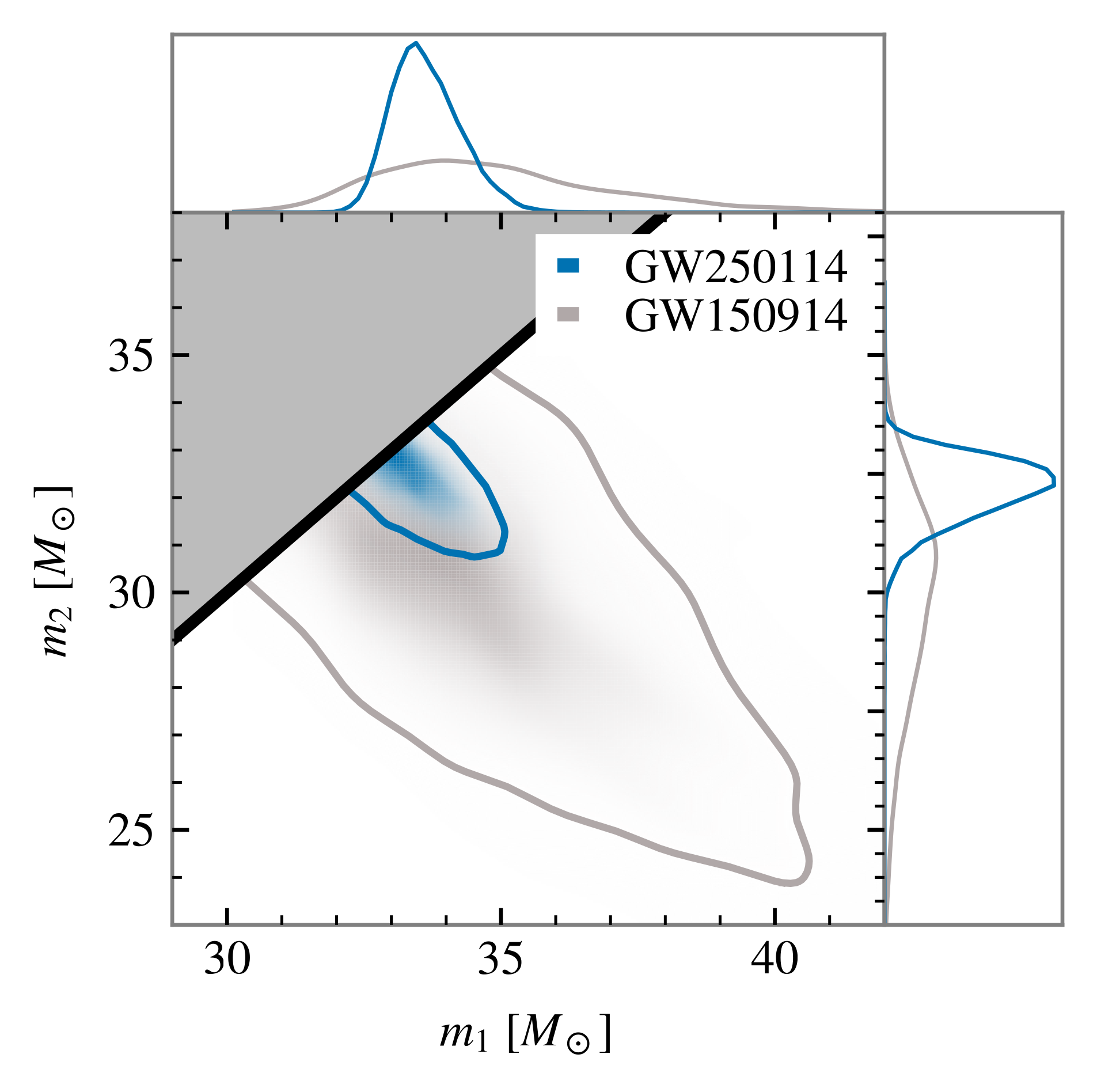
Figure 1: Posterior distribution on the component masses of GW250114. Adapted from Abac et al. (2025).
Standard approach: Nested Sampling
We can then sample with DYNESTY.
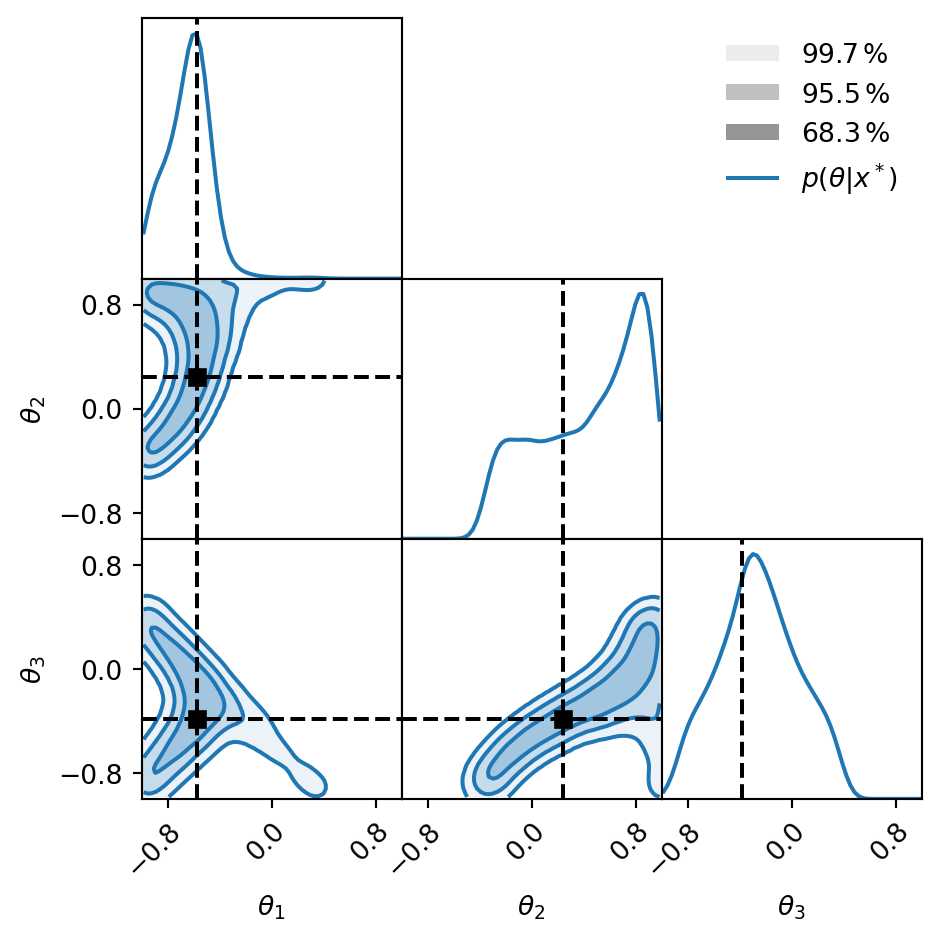
New approach: NPE
estimator = NPE(*args, **kwargs)
loss = NPELoss(estimator)
loader = JointLoader(prior, simulator)
optimizer = optim.Adam(
estimator.parameters())
step = GDStep(optimizer)
for epoch in range(16):
losses = []
for theta, x in islice(loader, 256):
losses.append(
step(loss(theta, x)))
samples = (estimator.flow(x_obs)
.sample((2**16,))
)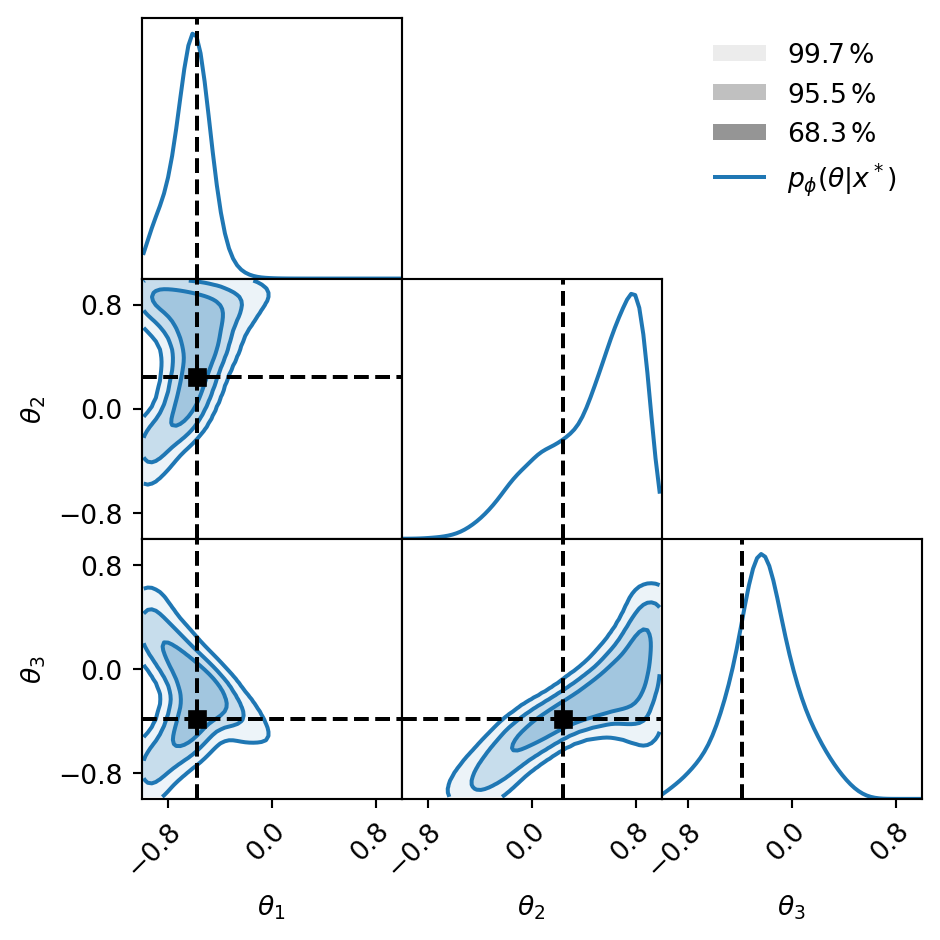
Weighted posterior
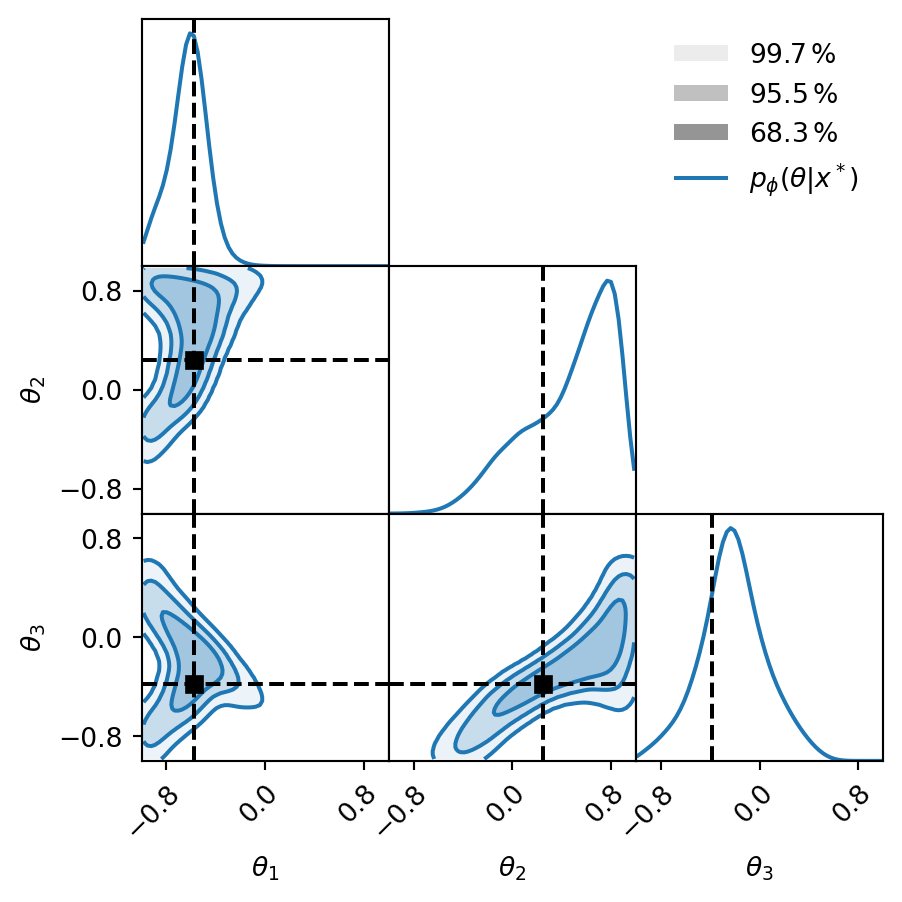
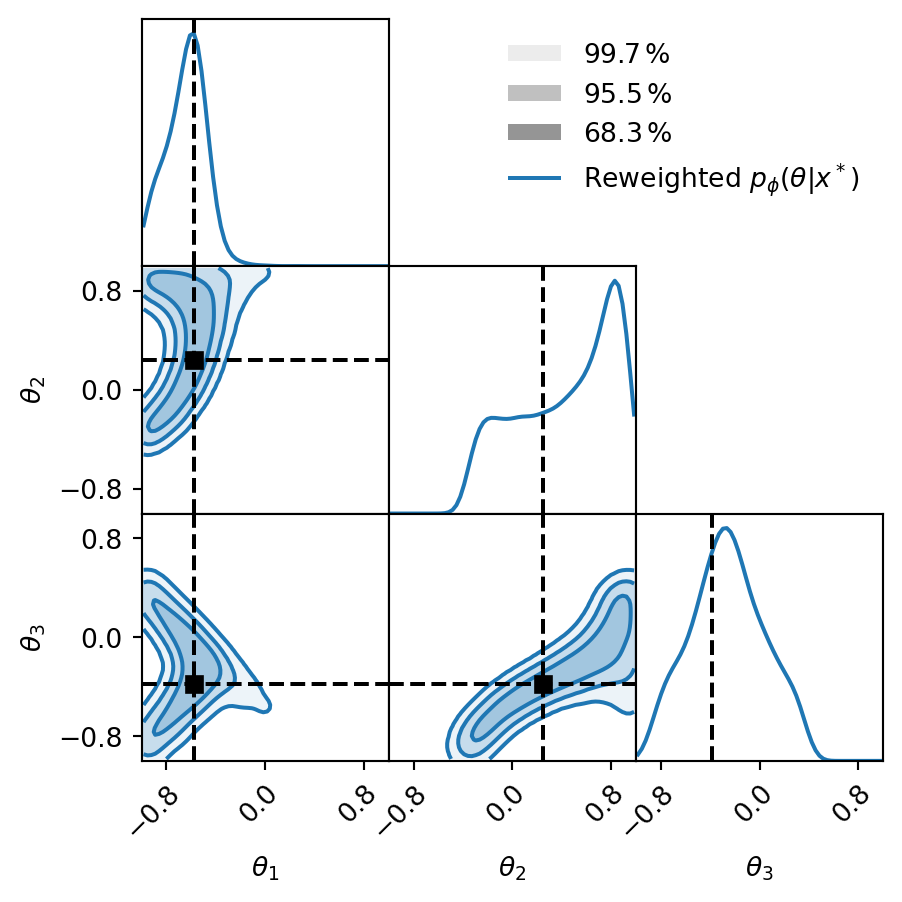
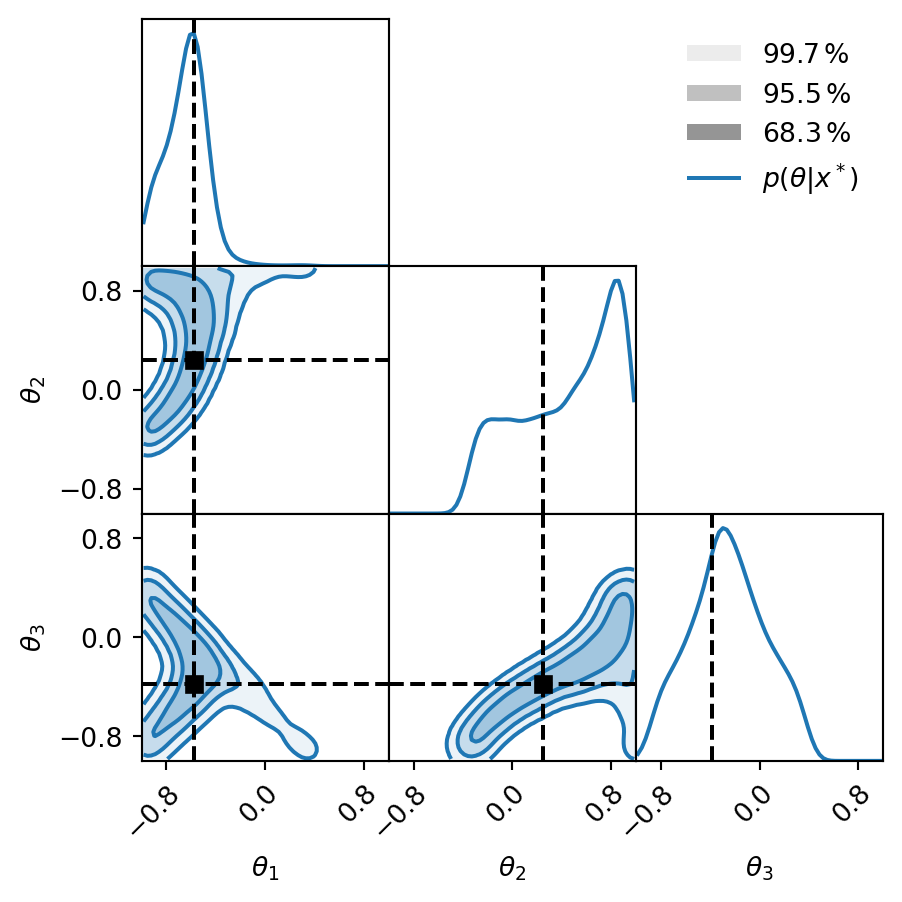
Weighted samples comparison
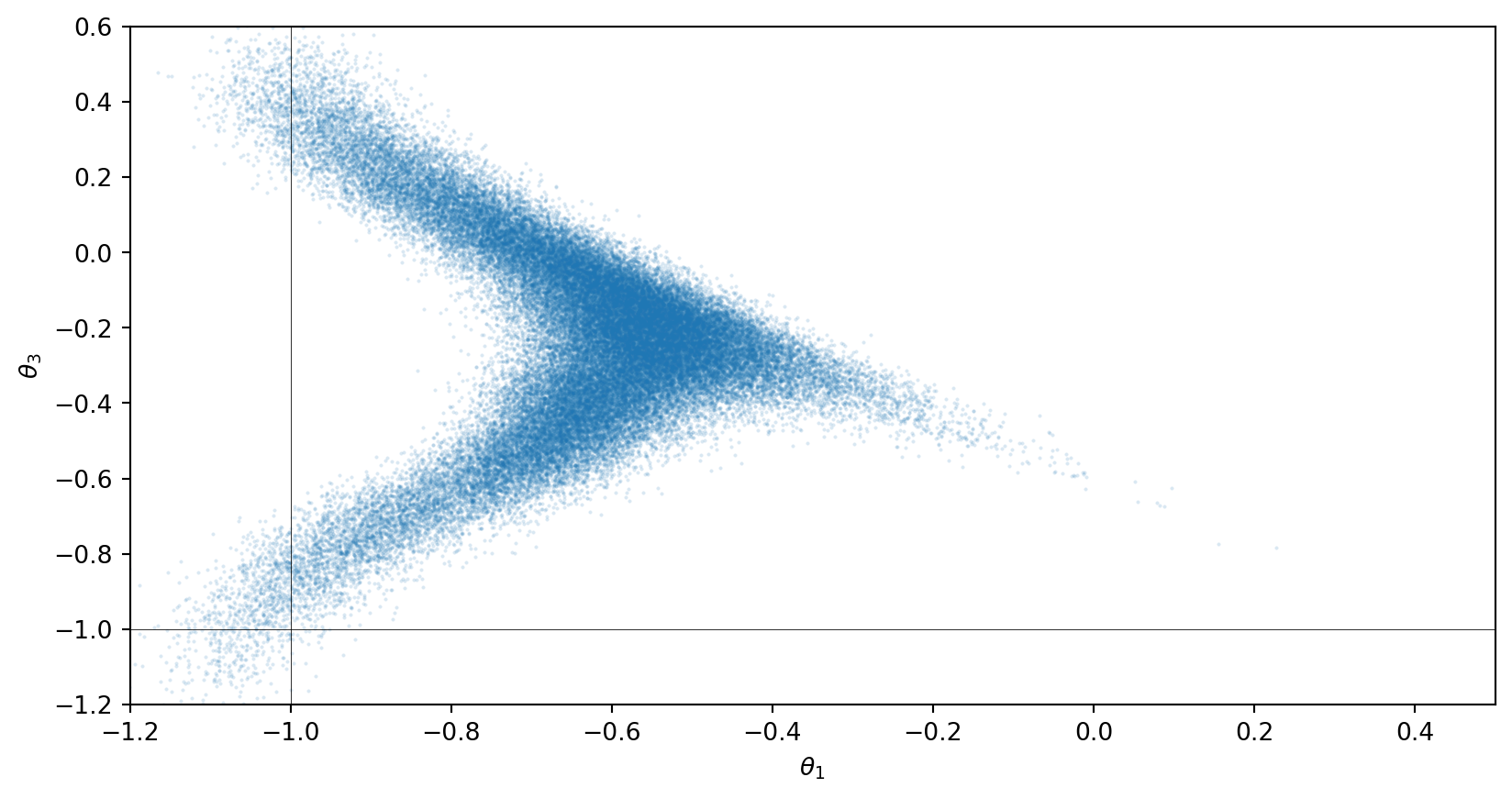
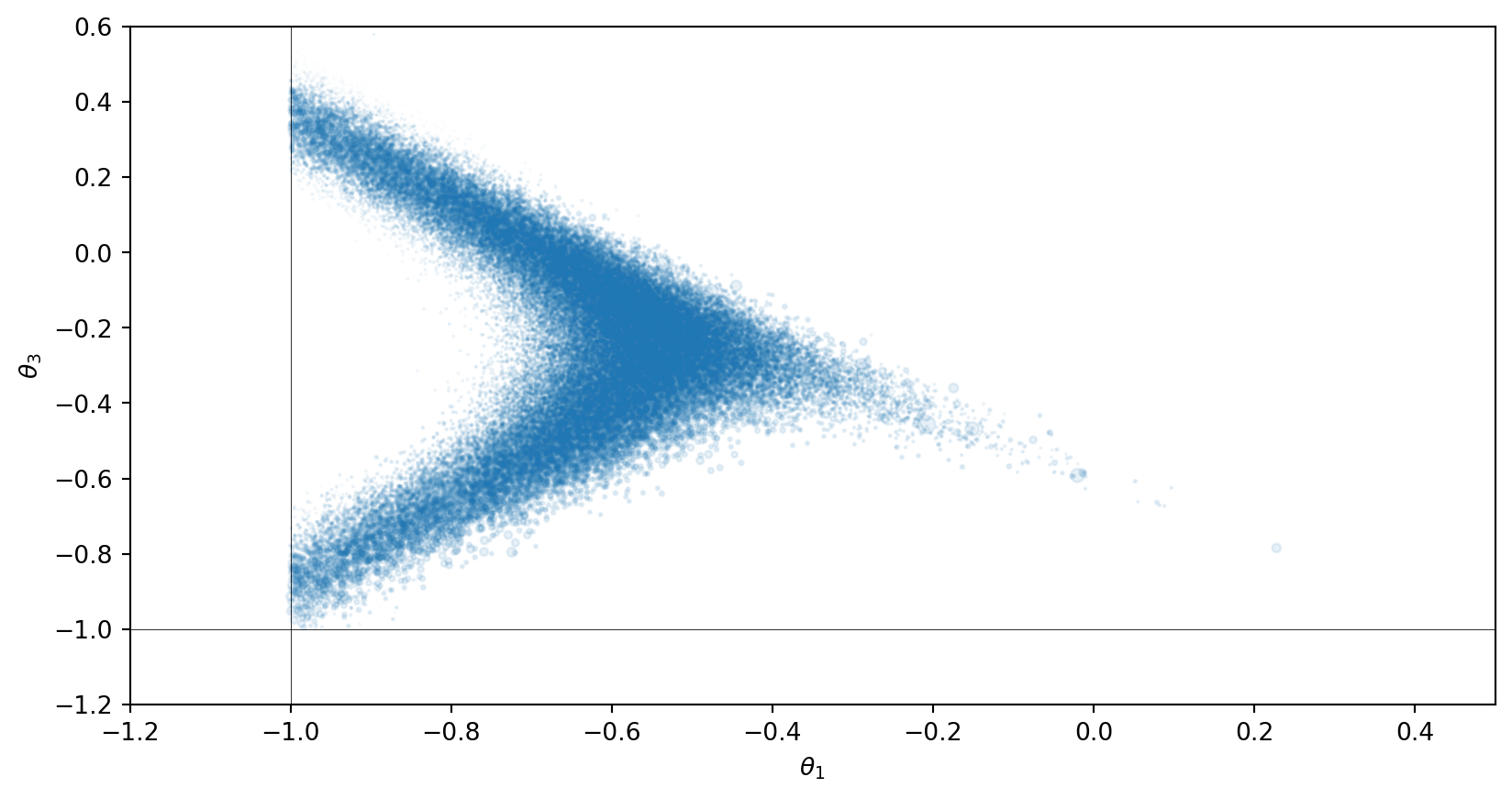
The arrival time problem
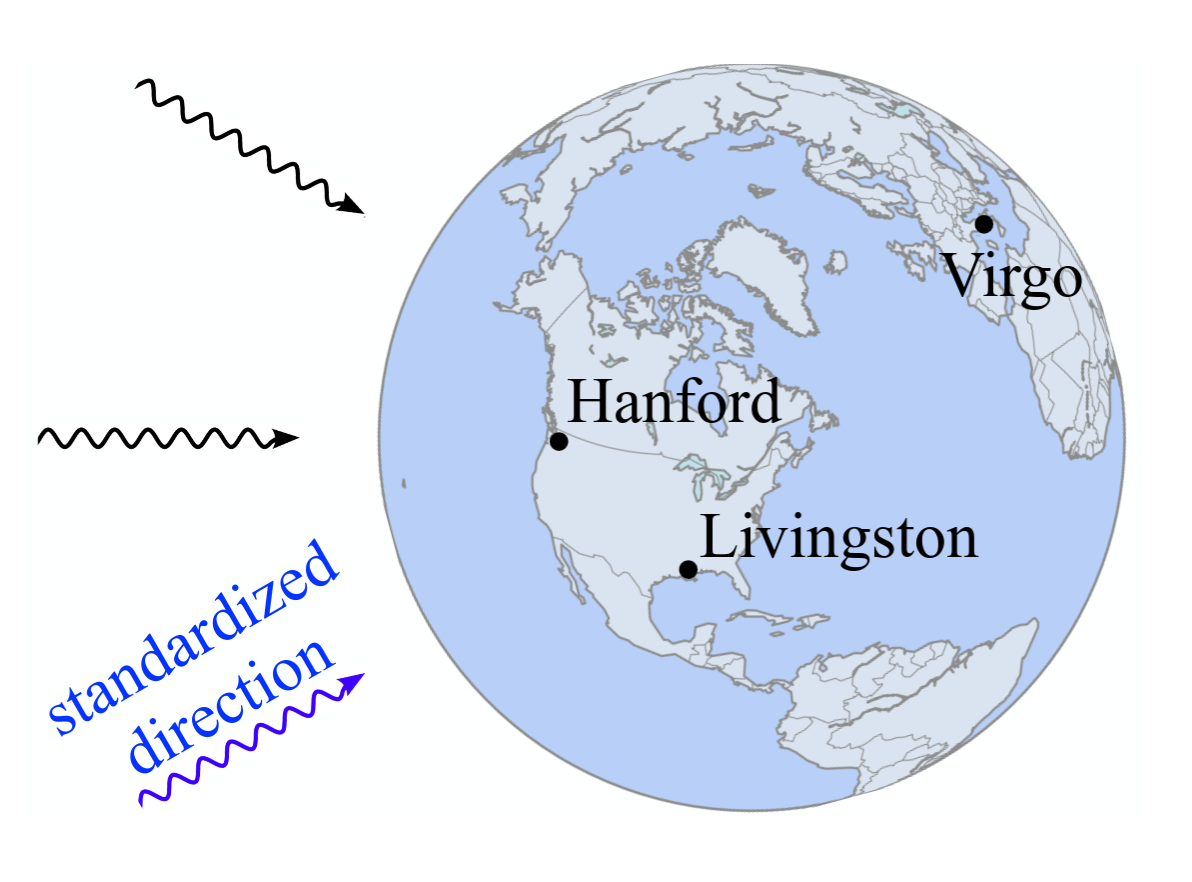
Standardization of the arrival direction (Dax et al. 2023).
Sample efficiency
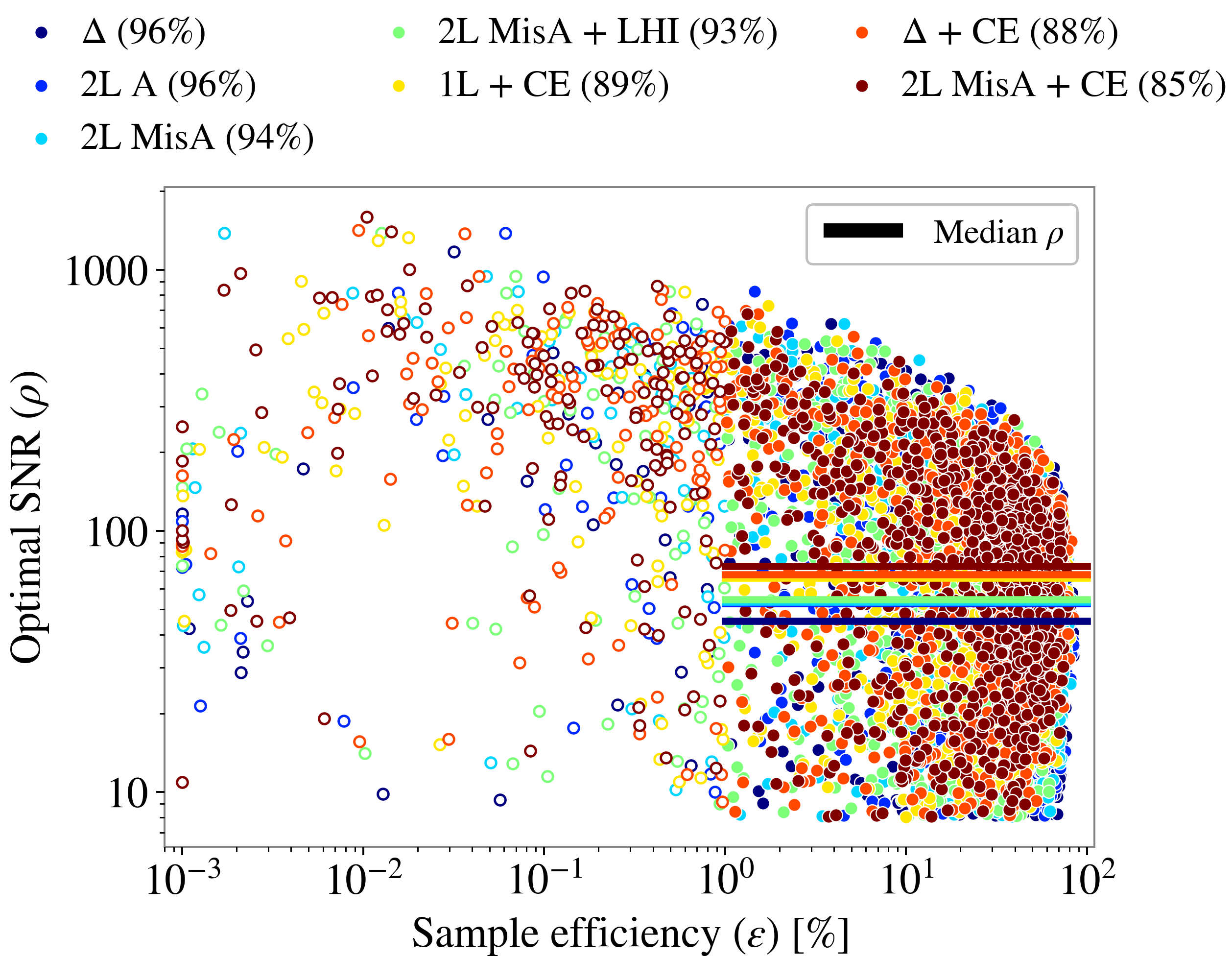
Sample efficiency as a function of SNR (Santoliquido et al. 2025).